- 11 Posts
- 18 Comments


 2·9 days ago
2·9 days agoI think those are all good questions that I don’t think anyone really have conclusive answers to (yet). Hopefully the researchers will have the funds in the future to investigate those and more!
From the article:
Squeezed in alongside their main projects, the investigation took eight years and included dozens of participants. The results, published in 2016, were revelatory [1]. Two to three months after giving birth, multiple regions of the cerebral cortex were, on average, 2% smaller than before conception. And most of them remained smaller two years later. Although shrinkage might evoke the idea of a deficit, the team showed that the degree of cortical reduction predicted the strength of a mother’s attachment to her infant, and proposed that pregnancy prepares the brain for parenthood.

I think that hypothesis still holds as it has always assumed training data of sufficient quality. This study is more saying that the places where we’ve traditionally harvested training data from are beginning to be polluted by low-quality training data
From the article:
To demonstrate model collapse, the researchers took a pre-trained LLM and fine-tuned it by training it using a data set based on Wikipedia entries. They then asked the resulting model to generate its own Wikipedia-style articles. To train the next generation of the model, they started with the same pre-trained LLM, but fine-tuned it on the articles created by its predecessor. They judged the performance of each model by giving it an opening paragraph and asking it to predict the next few sentences, then comparing the output to that of the model trained on real data. The team expected to see errors crop up, says Shumaylov, but were surprised to see “things go wrong very quickly”, he says.

What they see as “bad research” is looking at an older cohort without taking into consideration their earlier drinking habits - that is, were they previously alcoholics or did they generally have other problems with their health?
If you don’t correct for these things, you might find that people who are not drinking seems less healthy than people who are. BUT, that’s not because they’re not drinking, it’s just because of their preexisting conditions. Their peers who are drinking a little bit tend to not have these preexisting conditions (on average)
Here’s an actual explanation of the ‘sneaked reference’:
However, we found through a chance encounter that some unscrupulous actors have added extra references, invisible in the text but present in the articles’ metadata, when they submitted the articles to scientific databases. The result? Citation counts for certain researchers or journals have skyrocketed, even though these references were not cited by the authors in their articles.

 2·4 months ago
2·4 months agoThank you, those are some good points!
Could you explain a bit more about why it’s insane to have it as a docked volume instead of a mount point on the host? I’m not too well-versed with docker (or maybe hosting in general)
Edit: typo
Interesting that they have such a greedy/stupid bot

 2·4 months ago
2·4 months agoI would say no. Just as it’s not legitimate for any other business to break the law even if that means they’re not going to be profitable
Could it be this fella who’s hitting you up: https://claude.ai/login

 2·6 months ago
2·6 months agoFurther, most of the times, it’s simply infeasible to test the data in-depth. We’re all humans with busy schedules and it is, unfortunately, not trivial to replicate experiments. If a reviewer feels more data is needed to support a claim, they can ask for a follow-up test or experiment, but it has to be within reason

Yea, not the most clear title about what the article is about hahah

Seeing the edit, yes, but that is also wrong. As the first line of the link says, radiation therapy uses ionizing radiation and not microwaves
It is possible to use microwaves for treating cancer (see https://www.bmc.org/content/microwave-ablation), but the two aforementioned methods do not use them (with the caveat that both “chemotherapy” and “radiation therapy” are very broad categories)

Absolutely not
From the method section of the paper:
Materials and Property Characterization. From a popular US chain store, two brands of baby food containers made of polypropylene and one brand of reusable food pouch with- out material information on the label were purchased. The selection of polypropylene containers was based on its widespread use in baby food packaging. These choices aimed to showcase diverse types of baby food packaging. The food containers and the food pouch were analyzed for their semicrystalline structure and thermal stability by DSC using a Q200 differential scanning calorimeter (TA Instruments, New Castle, DE). Briefly, a small sample weighing between 3 and 8 mg was taken from each container or pouch, placed in a DSC aluminum pan/lid assem- bly, and crimped with a press. The samples were heated and cooled at a rate of 10 °C/min under a nitrogen atmosphere, resulting in calori- metric curves that indicate the heat transfer to and from the polymer sample during the thermal cycle, which was used to monitor phase transitions. H u s s a i n e t a l . i n E n v i r o n . S c i . T e c h n o l . 5 7 ( 2 0 2 3 ) 5 Transmission wide-angle X-ray diffraction (WAXD) of the reusable food pouch was performed at the 12-ID-B beamline at the Advanced Pho- ton Source (Argonne National Laboratory), using incident X-rays with energy 13.30 keV and a Pilatus 300k 2D detector mounted 0.4 m from the sample. WAXD patterns of the two plastic containers were acquired in reflection geometry with a Bruker-AXS D8 Discover equipped with a Cu Kα lab source (λ = 1.5406 A) and a Vantec 500 area detector. In all cases, the acquired 2D patterns were radially averaged to produce 1D intensity (I) vs scattering vector (q) plots
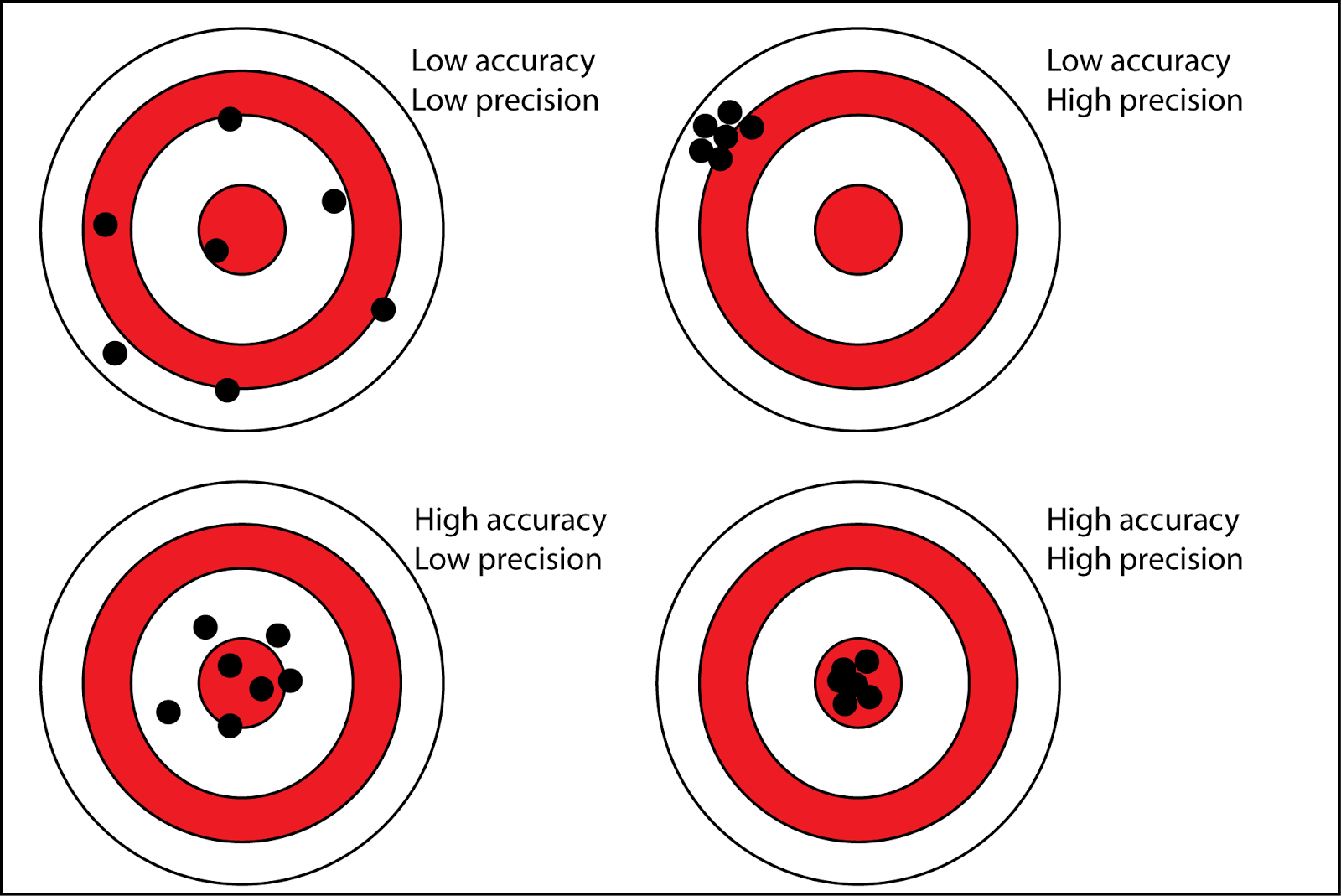
When talking about measurements, “precision” and “accuracy” have slightly different meanings See here

{kind=link}
That’s a super cool link. Thanks for sharing!